Table of Contents
What is Data Stage ?
Data Stage is comprised of two separate things. In production/development/Test environments it is just another application on the server which connects to data sources & targets and processes or transforms the data as they move through the application. It is classed as an ETL tool and its jobs are executed on a single server or multiple machines in a cluster/grid environment. Like all other applications, these jobs consume computer resources and network bandwidth. It has well defined Windows-based graphical tools that allow ETL processes to be designed, managing the metadata associated with them, and monitoring the ETL processes. These tools connect to the Data Stage server as all the design and metadata information are stored on the server.
Steps involved in Data Stage
- Design jobs for Extraction, Transformation, and Loading (ETL)
- Ideal tool for data integration projects – such as data warehouses, data marts, and system migrations
- Import, export, create, and manage metadata for use within jobs
- Schedule, run, and monitor jobs all within Data Stage
- Administer the Data Stage development and execution environments
- Create batch (controlling) jobs
What is Data Stage Engines ?
There are two different engines namely Server and Parallel engines. The first one is the original Data Stage engine and, as its name suggests, is used to run the jobs on the server. The later one i.e. parallel engine results uses a different technology that enables work and data to be distributed over multiple logical “processing nodes” whether these are in a single machine or multiple machines in a cluster or grid configuration. It also allows the degree of parallelism to be changed without change to the design of the job.
Data stage Architecture
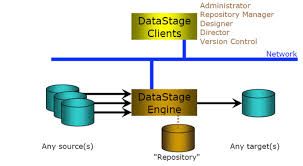
Below are the different types of Data Stage clients
Data Stage Administrator
- Configuration tasks are carried out using the Administrator (a client program provided with Data Stage).
- They are used for adding / creating / deleting the projects.
- Project Properties are set using these options. They also provides the command line interface to the Data Stage repository and can perform different settings of the project using Data Stage Administrator like
- Setting Up Data Stage Users in Administrator.
- We can create, delete, and move the Data Stage projects from one place to another place.
- We can clean up the project files which are not required.
- We can purge the job log files.
- We can set the job properties in Data Stage Administrator.
- We can trace the Server Activity.
Data Stage Manager
- Used to store and manage re-usable metadata for the jobs.
- Used to import and export components from file-system to Data stage projects.
- Primary interface to the Data Stage Repository.
- Custom routines and transforms can also be created in the Manager.
Data Stage Designer
- Create Jobs that are compiled into executable programs.
- Design the jobs that extract, integrate, aggregate, load, and transform the data.
- Create and reuse metadata and job components.
- Allows users to use familiar graphical point-and-click techniques to develop processes for extracting, cleansing, transforming, Integrating and loading data.
- Specify how data is extracted.
- Specify data transformations.
- Decode data going into the target tables using reference lookups.
- Aggregate Data.
- Split data into multiple outputs on the basis of defined constraints.
Data Stage Director
- This is the client component that validates, runs, schedules, and monitors jobs run by the Data Stage Server.
- It is the starting point for most of the tasks a Data Stage operator needs to do in respect of Data Stage jobs.
Key Data Stage components
Below are the key components of Data Stage which is explained in brief.
Project
- Usually created for each application (or version of an application, e.g. Test, Dev, etc.)
- Multiple projects can exist on a single server box
- Associated with a specific directory with the same name as the Project: the “Repository”, which contains all metadata associated with the project
- Consists of Data Stage Server & Parallel Jobs, Pre-built components (Stages, Functions, etc.), User-defined components
- User Roles & Privileges set at this level
- Managed through the DS Administrator client tool
- Connected to through other client components
Category
- Folder-structure within the Project.
- Separate “Trees” for Jobs, Table Definitions, Routines, etc.
- Managed through the DS Manager client tool
- Used for better organization of project components.
Table Definition
- Metadata: record structure with column definitions
- Can be imported or manually entered
- Created using the DS Manager client tool
- Not necessarily associated with a specific table or file.
- Association only made within the job (and stage) definition
- Metadata definition also possible directly through the Stage, but may not result in creation of a table definition
Schema Files
- External metadata definition for a sequential file. Specific format & syntax for a file. Associated with a data file at run-time.
Job
- Executable unit of work that can be compiled & executed independently or as part of a data flow stream
- Created using DS Designer Client (Compile & Execute also available through Designer)
- Managed (copy, rename) through DS Manager
- Executed, monitored through DS Director, Log also available through Director
- Parallel Jobs (Available with Enterprise Edition)
- have built-in functionality for Pipeline and Partitioning Parallelism
- Compiled into OSH (Orchestrate Scripting Language).
- The OSH executes “Operators” which are executable C++ class instances
- Server Jobs (Available with Enterprise as well as Server Editions)
- Compiled into Basic (interpreted pseudo-code)
- Limited functionality and parallelism can accept parameters
- Reads & writes from one or more files/tables, may include transformations
- Collection of stages & links
Stages
Pre-built component to
- Perform a frequently required operation on a record or set or records, e.g. Aggregate, Sort, Join, Transform, etc.
- Read or write into a source or target table or file
Links
- Depicts flow of data between stages
Data Sets
- Data is internally carried through links in the form of Data Sets
- Data Stage provides facility to “land” or store this data in the form of files
- Recommended for staging data as the data is partitioned & sorted data; so a fast way of sharing/passing data between jobs
- Not recommended for back-ups or for sharing between applications as it is not readable, except through Data Stage
Shared Containers
- Reusable job elements – comprises of stages and links
Routines
- Pre-built & Custom built
- Two Types
- Before/After Job: Can be executed before or after a job( or some stages), multiple input arguments, returns a single error code
- Transform: Called within a Transform Stage to process record & produce a single return value that can be allocated to or used in computation of an output field
- Custom Built
- Written & compiled using a C++ utility. The Object File created is registered as a routine & is invoked from within Data Stage
Note that server jobs use routines written within the DS environment using an extended version of the BASIC language
Job Sequence
- Definition of a workflow, executing jobs (or sub sequences), routines, OS commands, etc.
- Can accept specifications for dependency, e.g.
- when file A arrives, execute Job B
- Execute Job A, On Failure of Job A Execute OS Command <> On Completion of Job A execute Job B & C
- Can invoke parallel as well as server jobs
DS API
- SDK functions
- Can be embedded into C++ code, invoked through the command line or from shell scripts
- Can retrieve information, compile, start, & stop jobs
Configuration File
- Defines the system size & configuration applicable to the job, in terms of nodes, node pools, mapped to disk space & assigned scratch disk space.
- Details maintained external to the job design.
- Different files can be used according to individual job requirements.
Environment Variables
- Set or defined through the Administrator at a project level
- Overridden at a job level
- Types
- Standard/Generic Variables: design and running of parallel jobs: e.g. buffering, message logging, etc.
- User Defined Variables
DSX or XML files
- Created through export option
- Can select components by type, category & name
Data Stage features
- Source & Target data supported
- SEQUENTIAL FILESTAGE
- TRANSFORMER STAGE
- JOIN STAGE
- AGREEGATOR STAGE
- JOB PARAMETERS
Source & Target data supported
- Text files
- Complex data structures in XML
- Enterprise application systems such as SAP, PeopleSoft, Siebel and Oracle Applications
- Almost any database – including partitioned databases, such as Oracle, IBM DB2 EE/EEE/ESE (with and without DPF), Informix, Sybase, Teradata, SQL Server, and the list goes on including access using ODBC
- Web services
- Messaging and EAI including WebSphereMQ and SeeBeyond
- SAS
- Data Stage is National Language Support (NLS) enabled using Unicode.
- 400 pre-built functions and routines
- Job templates & wizards
- Data Stage uses the OS-level security for restricting access to projects.
- Only root/admin user can administer the server
- Roles can be assigned to users & groups to control access to projects
SEQUENTIAL FILESTAGE
- Features
- Normally executes in sequential mode
- Can read from multiple files with same metadata
- Can accept wild-card path & names.
- The stage needs to be told:
- How file is divided into rows (record format)
- How row is divided into columns (column format)
- Stage Rules
- Accepts 1 input link OR 1 stream output link
- Rejects record(s) that have metadata mismatch. Options on reject
- Continue: ignore record
- Fail: Job aborts
- Output: Reject link metadata a single column, not alterable, can be written into a file/table
- Features of Copy Stage
- Copies single input link dataset to a number of output datasets
- Records can be copied with or without some modifications
- Modifications can be:
- Drop columns
- Change the order of columns
- Note that this functionality also provided by the Transform Stage but Copy is faster
TRANSFORMER STAGE
- Single input
- One or more output links
- Optional Reject link
- Column mappings – for each output link, selection of columns & creation of new derived columns also possible
- Derivations
- Expressions written in Basic
- Final compiled code is C++ generated object code (Specified compiler must be available on the DS Server)
- Powerful but expensive stage in terms of performance
- Stage variables
- For readability & for performance when same complex expression is used in multiple derivations
- Be aware that
- The values are retained across rows & order of definition of stage variables will matter.
- The values are retained across rows but only within a each partition
- Expressions for constraints and derivations can reference
- Input columns
- Job parameters
- Functions (built-in or user-defined)
- System variables and constants
- Stage variables – be aware that the variables are within each partition
- External routines
- Link Ordering – to use derivations from previous links
- Constraints
- Filter data
- Direct data down different output links
- For different processing or storage
- Output links may also be set to be “Otherwise/Log” to catch records that have not passed through any of the links processed so far (link ordering is critical)
- Optional Reject link to catch records that failed to be written into any output because of write errors or NULL
JOIN STAGE
- Four types: This consists of Inner, Left outer, Right outer ,Full outer joins
- Follow the RDBMS-style relational model
- Cross-products in case of duplicates
- Matching entries are reusable for multiple matches
- Non-matching entries can be captured (Left, Right, Full)
- Join keys must have same name, can modify if required in a previous stage
- 2 or more input links, 1 output link
- No fail/reject option for missed matches
- All input link data is pre-sorted & partitioned** on the join key
- By default – Sort inserted by Data Stage
- If data is pre-sorted (by a previous stage), does not pre-sorts
AGREEGATOR STAGE
- Performs data aggregations
- Specify zero or more key columns that define the aggregation units (or groups)
- Aggregation functions available are:
- Count (nulls/non-nulls)
- Sum
- Max/Min/Range/Mean
- Missing/Non-missing value count
- % coefficient of variation
- Output link has “Mapping” tab to select, reorder & rename fields
- Input key-partitioned** on grouping columns
- Grouping methods available are:
- Hash
- Intermediate results for each group are stored in a hash table
- Final results are written out after all input has been processed
- No sort required
- Use when number of unique groups is small
- Running tally for each group’s aggregate calculations needs to fit into memory. Requires about 1K RAM / group
- Sort
- Only a single aggregation group is kept in memory
- When new group is seen, current group is written out
- Requires input to be sorted by grouping keys
- Can handle unlimited numbers of groups
- Example: average daily balance by credit card
JOB PARAMETERS
- Setting Parameter Values
- Provided at run-time
- Use default value used if not reset
- If no default value, the value must be provided at run-time
Benefits of using Data Stage tool
- Flexibility, ease of support, and extendibility—without writing expensive custom code
- Increased speed and performance of the data warehouse
- Plug-in to Data Stage is efficient when compare to any other ETL or EAI tools
- Supports the collection, integration and transformation of high volumes of data from different SAP systems, with data structures ranging from simple to highly complex. Data Stage manages data arriving in real-time as well as data received daily, weekly or monthly
- Supports a virtually unlimited number of heterogeneous data sources and targets in a single job, including: text files; complex data structures in XML; ERP systems such as SAP and PeopleSoft; almost any database (including partitioned databases), web services, and SAS
Basic Error types in DataStage
Below are the basic errors that will be found in Data Stage testing either while compiling the jobs or running the jobs.
- Source file not found – If you are trying to read the file, which was not there with that name.
- Fatal Errors.
- Data type mismatches – This will occur when data type mismatches occurs in the jobs.
- Field Size errors.
- Meta data Mismatch
- Data type size between source and target different
- Column Mismatch
- Priceless time out – If server is busy. This error will come sometime.


