Table of Contents
Data Mining
Data mining (knowledge discovery from data).Extraction of interesting (non-trivial, implicit, previously unknown and potentially useful) patterns or knowledge from huge amount of data.
Alternative names of data mining :
Knowledge discovery (mining) in databases (KDD), knowledge extraction, data/pattern analysis, data archeology, data dredging, information harvesting, business intelligence, etc.
What is not Data Mining?
- Look up phone number in phone directory
- Query a Web search engine for information about “Amazon”.
What is Data Mining?
- Certain names are more prevalent in certain US locations (O’Brien, O’Rurke, O’Reilly… in Boston area)
- Group together similar documents returned by search engine according to their context (e.g. Amazon rainforest, Amazon.com,)
Origins of Data Mining
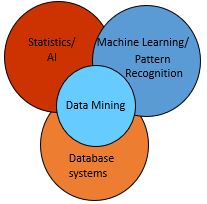
- Draws ideas from machine learning/AI, pattern recognition, statistics, and database systems
- Traditional Techniques may be unsuitable due to
- Enormity of data
- High dimensionality of data
- Heterogeneous, distributed nature of data
Data Mining & Machine Learning
According to Tom M. Mitchell, Chair of Machine Learning at Carnegie Mellon University and author of the book Machine Learning (McGraw-Hill),
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with the experience E.
We now have a set of objects to define machine learning:
Task (T), Experience (E), and Performance (P)
With a computer running a set of tasks, the experience should be leading to performance increases (to satisfy the definition)
Many data mining tasks are executed successfully with help of machine learning
Data Mining on Diverse kinds of Data
Besides relational database data (from operational or analytical systems), there are many other kinds of data that have diverse forms and structures and different semantic meanings.
Examples of data can be :
- time-related or sequence data (e.g., historical records, stock exchange data, and time-series and biological sequence data),
- data streams (e.g., video surveillance and sensor data, which are continuously transmitted),
- spatial data (e.g., maps),
- engineering design data (e.g., the design of buildings, system components, or integrated circuits),
- hypertext and multimedia data (including text, image, video, and audio data),
- graph and networked data (e.g., social and information networks), and
- the Web (a widely distributed information repository).
Diversity of data brings in new challenges such as handling special structures (e.g., sequences, trees, graphs, and networks) and specific semantics (such as ordering, image, audio and video contents, and connectivity).
Why Data Mining ?
- The Explosive Growth of Data: from terabytes to petabytes
- Data collection and data availability
- Automated data collection tools, database systems, Web, computerised society.
- Major sources of abundant data
- Business: Web, e-commerce, transactions, stocks,
- Science: Remote sensing, bioinformatics, scientific simulation,
- Society and everyone: news, digital cameras, YouTube
- Data collection and data availability
- We are drowning in data, but starving for knowledge!
- “Necessity is the mother of invention”—Data mining—Automated analysis of massive data sets.
Data mining process
The standard data mining process involves
- understanding the problem,
- preparing the data (samples),
- developing the model,
- applying the model on a data set to see how the model may work in real world, and
- production deployment.
A popular data mining process frameworks is CRISP-DM (Cross Industry Standard Process for Data Mining). This framework was developed by a consortium of companies involved in data mining.
Generic Data mining process
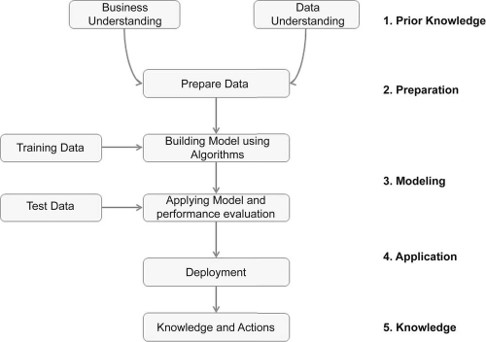
Prior Knowledge
- Data Mining tools/solutions identify hidden patterns.
- Generally we get many patterns
- Out of them many could be false or trivial.
- Filtering false patterns requires domain understanding.
- Understanding how the data is collected, stored, transformed, reported, and used is essential.
- Causation vs. Correlation
- A bank may decide interest rate based on credit score. Looking at data, credit score moves as per interest rate. It does not make sense to derive credit score from interest rate.
Data Preparation
- Data needs to be understood. It requires descriptive statistics such as mean, median, mode, standard deviation, and range for each attribute
- Data quality is an ongoing concern wherever data is collected, processed, and stored.
- The data cleansing practices include elimination of duplicate records, quarantining outlier records that exceed the bounds, standardization of attribute values, substitution of missing values, etc.
- it is critical to check the data using data exploration techniques in addition to using prior knowledge of the data and business before building models to ensure a certain degree of data quality
- Missing Values
- Need to track the data lineage of the data source to find right solution
- Data Types and Conversion
- The attributes in a data set can be of different types, such as continuous numeric (interest rate), integer numeric (credit score), or categorical
- data mining algorithms impose different restrictions on what data types they accept as inputs
- Transformation
- Can go beyond type conversion, may include dimensionality reduction or numerosity reduction
- Outliers are anomalies in the data set
- May occur legitimately or erroneously.
- Feature Selection
- Many data mining problems involve a data set with hundreds to thousands of attributes, most of which may not be helpful. Some attributes may be correlated, e.g. sales amount and tax.
- Data Sampling may be adequate in many cases
Modeling
A model is the abstract representation of the data and its relationships in a given data set.
Data mining models can be classified into the following categories: classification, regression, association analysis, clustering, and outlier or anomaly detection.
Each category has a few dozen different algorithms; each takes a slightly different approach to solve the problem at hand.
Application
- The model deployment stage considerations:
- assessing model readiness, technical integration, response time, model maintenance, and assimilation
- Production Readiness
- Real-time response capabilities, and other business requirements
- Technical Integration
- Use of modeling tools (e.g. RapidMiner), Use of PMML for portable and consistent format of model description, integration with other tools
- Timeliness
- The trade-offs between production responsiveness and build time need to be considered
- Remodeling
- The conditions in which the model is built may change after deployment
- Assimilation
- The challenge is to assimilate the knowledge gained from data mining in the organization. For example, the objective may be finding logical clusters in the customer database so that separate treatment can be provided to each customer cluster.



Hello. I see that you don’t update your page too often. I know that writing content is time consuming and boring.
But did you know that there is a tool that allows you
to create new articles using existing content (from article directories or other blogs from your niche)?
And it does it very well. The new articles are high quality and pass the copyscape test.