Table of Contents
BIG Data Analytics
BIG Data Analytics is like a mountain of data that you have to climb.The height of the mountain keeps increasing everyday and you have to climb it in less time than yesterday!!
- This is the kind of challenge big data throws at us
- Has forced us to go back to the drawing board and design every aspect of a compute system afresh
- Has spawned research in every sub area of Computer Science
What Is Big Data ?
There is no consensus as to how to define big data
“Big data exceeds the reach of commonly used hardware environments and software tools to capture, manage, and process it with in a tolerable elapsed time for its user population.” – Teradata Magazine article, 2011
“Big data refers to data sets whose size is beyond the ability of typical database software tools to capture, store, manage and analyze.” – The McKinsey Global Institute, 2011
BIG DATA poses a big challenge to our capabilities
- Data scaling outdoing scaling of compute resources
- CPU speed not increasing either
At the same time, BIG DATA offers a BIGGER opportunity to
- Understand nature
- Understand evolution
- Understand human behavior/psychology/physiology
- Understand stock markets
- Understand road and network traffic
- Opportunity for us to be more and more innovative.
Big Data – Sources
- Telecom data (» 4.75 bn mobile subscribers)
- There are 3 Billion Telephone Calls in US each day,
30 Billion emails daily, 1 Billion SMS, IMs. - IP Network Traffic: up to 1 Billion packets per hour per router. Each ISP has many (hundreds) routers!
- WWW
- Weblog data (160 mn websites)
- Email data
- Satellite imaging data
- Social networking sites data
- Genome data
- CERN’s LHC (15 petabytes/year)
- Just a Hype?
- Or a real Challenge?
- Or a great Opportunity?
- Challenge in terms of how to manage & use this data
- Opportunity in terms of what we can do with this data to enrich the lives of everybody around us and to make our mother Earth a better place to live
- We are living in a world of DATA!!
- We are generating more Data that we can handle!!!
- Using Data to our benefit is a far cry!!!
- In future, everything will be Data driven
- High time we figured out how to tame this “monster” and use it for the benefit of the society.
Another Interesting Quote
“We don’t have better Algorithms, We just have more data”
– Peter Norvig, Director of Research, Google
Analyzing BIG DATA
Data analysis, organization, retrieval, and modeling are other foundational challenges. Data analysis is a clear bottleneck in many applications, both due to lack of scalability of the underlying algorithms and due to the complexity of the data that needs to be analyzed*
*Challenges and Opportunities with Big Data
A community white paper developed by leading researchers across the United States
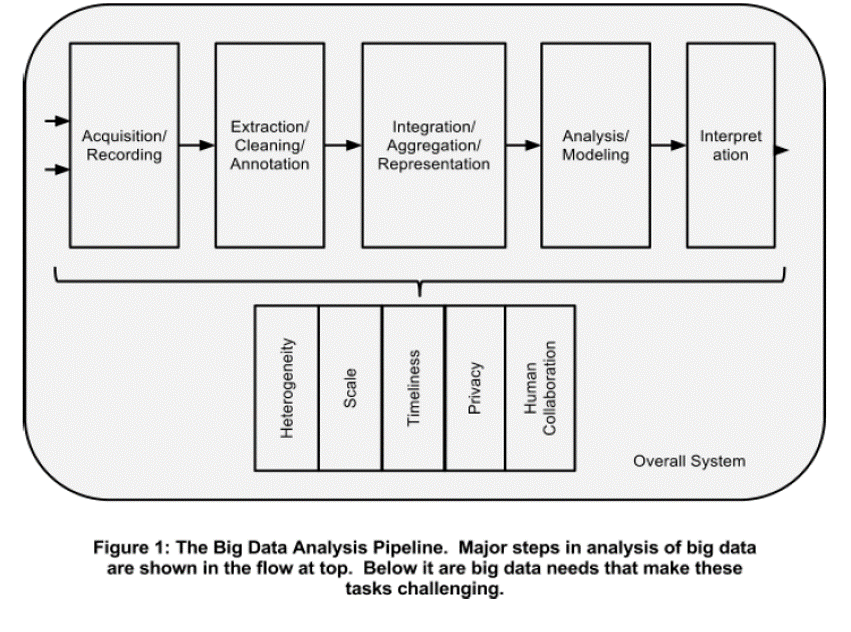
Source:Challenges and Opportunities with Big Data
A community white paper developed by leading researchers across the United States.
BIG DATA is spawning research in:
- Databases
- Data Analytics (Data Warehousing, Data Mining & Machine Learning)
- Parallel Programming & Programming Models
- Distributed and High Performance Computing
- Domain Specific Languages
- Storage Technologies
- Algorithms & Data Structures
- Data Visualization
- Architecture
- Networks
- Green Computing
Data Warehousing, Data Mining & Machine Learning are at the core of BIG Data Analytics
Why Cluster Computing ?
- Scalable
- Only way forward to deal with Big Data
- Embrace this technology till any new disruptive/revolutionary technology surfaces
Extended RDBMS Architecture
- Support for new data types required by BIG data
- Vectors & matrices
- Multimedia data
- Unstructured and semi-structured data
- Collection of name-value pairs, called as data bags
- Provide support for processing new data types within the DBMS inner loop by means of user-defined functions
MapReduce
- What’s there in a name?
- Everything!!
- Map + Reduce
- Both are functions used in “functional programming”
- Has primitives in LISP & other functional PLs
- So what is functional programming?
Google paper 2004: MapReduce: Simplified Data Processing on Large Clusters Jeffrey Dean and Sanjay Ghemawat OSDI, 2004
Functional Programming
- Functional programming is a programming paradigm that treats computation as the evaluation of mathematical functions
- Interactive PL
- Expression Value
- (function arg1 arg2 …argn)*
- (+ 12 23 34 45) 104
Scheme – a dialect of LISP, is the 2nd oldest PL that is still in use
- In early days computer use was very expensive, it was obvious to have the programming language resemble the architecture of the computer as close as possible.
- A computer consists of a central processing unit and a memory.
- Therefore a program consisted of instructions to modify the memory, executed by the processing unit
- With that the imperative programming style arose
- Imperative programming language, like Pascal and C, are characterized by the existence of assignments, executed sequentially.
- Functions express the connection between parameters (the ‘input’) and the result (the ‘output’) of certain processes.
- In each computation the result depends in a certain way on the parameters. Therefore a function is a good way of specifying a computation.
- This is the basis of the functional programming style.
- A ‘program’ consists of the definition of one or more functions
- With the ‘execution’ of a program the function is provided with parameters, and the result must be calculated.
- With this calculation there is still a certain degree of freedom
- For instance, why would the programmer need to prescribe in what order independent subcalculations must be executed?
- The theoretical basis of imperative programming was already founded in the 30s by Alan Turing (in England) and John von Neuman (in the USA)
- The theory of functions as a model for calculation comes also from the 20s and 30s. Some of the founders are M. Sch¨onfinkel (in Germany and Russia), Haskell Curry (in England) and Alonzo Church (in the USA
- The language Lisp of John McCarthy was the first functional programming language, and for years it remained the only one
- ML, Scheme (an adjustment to Lisp), Miranda and Clean are other examples of functional programming languages
- Haskell (first unified PL) & Gofer (a simplified version of Haskell)
- ML & Schemes have overtones of imperative programming languages and therefore are not purely FPLs
- Miranda is a purely FPL!
What is Gofer ?
? 5+2*3 11
(5 reductions, 9 cells) ?
- The interpreter calculates the value of the expression entered, where * denotes multiplication.
- After reporting the result (11) the interpreter reports the calculation took ‘5 reductions’ (a measure for the amount of time needed) and ‘9 cells’ (a measure for the amount of memory used)
- The question mark shows the interpreter is ready for the next expression
? sum [1..10]
55
(91 reductions, 130 cells)
- In this example [1..10] is the Gofer notation for the list of numbers from 1 to 10.
- The standard function sum can be applied to such a list to calculate the sum (55) of those numbers.
- A list is one of the ways to compose data, making it possible to apply functions to large amounts of data.
- Lists can also be the result of a function:
? sums [1..10]
[0, 1, 3, 6, 10, 15, 21, 28, 36, 45, 55]
(111 reductions, 253 cells)
- The standard function sums returns next to the sum of the numbers in the list also all the intermediate results.
? reverse (sort [1,6,2,9,2,7])
[9, 7, 6, 2, 2, 1]
(52 reductions, 135 cells)
- g (f x) means that f should be applied to x and g should be applied to the result of that
- Gofer is a largely parenthesis free language
Gofer: Defining New Functions
- The editor is called by typing ‘:edit’, followed by the name of a file, for example:
? :edit new
- Definition of the factorial function can be put in the file ‘new’.
- In Gofer the definition of the function fac could look like:
fac n = product [1..n]
? :load new
Reading script file “new”:
Parsing………………………………………………….
Dependency analysis……………………………………….
Type checking…………………………………………….
Compiling………………………………………………..
Gofer session for:
/usr/staff/lib/gofer/prelude
new
?
- Now fac can be used
? fac 6
720
(59 reductions, 87 cells)
Gofer: Adding fn to a file
- It is possible to add definitions to a file when it is already loaded. Then it is sufficient to just type :edit; the name of the file needs not to be specified.
- For example a function which can be added to a file is the function ‘n choose k’: the number of ways in which k objects can be chosen from a collection of n objects
- This definition can, just as with fac, be almost literally been written down in Gofer:
choose n k = fac n / (fac k * fac (n-k))
Example:
? choose 10 3
120
(189 reductions, 272 cells)
Gofer: Defining a New Operator
- A operator is a function with two parameters which is written between the parameters instead o fin front of them
- In Gofer it is possible to define your own operators
- The function choose from could have been defined as an operator, for example as !ˆ! :
n !^! k = fac n / (fac k * fac (n-k))
Gofer: Nesting Functions
- Parameter of a function can be a function itself too!
- An example of that is the function map, which takes two parameters: a function and a list.
- The function map applies the parameter function to all the elements of the list.
For example:
? map fac [1,2,3,4,5]
[1, 2, 6, 24, 120]
? map sqrt [1.0,2.0,3.0,4.0]
[1.0, 1.41421, 1.73205, 2.0]
? map even [1..8]
[False, True, False, True, False, True, False, True]
- Functions with functions as a parameter are frequently used in Gofer (why did you think it was called a functional language?).
MapReduce/Hadoop
- MapReduce* – A programming model & its associated implementation
- provides a high level of abstraction
- but has limitations
- Only data parallel tasks stand to benefit!
- MapReduce hides parallel/distributed computing concepts from users/programmers
- Even novice users/programmers can leverage cluster computing for data-intensive problems
- Cluster, Grid, & MapReduce are intended platforms for general purpose computing
- Hadoop/PIG combo is very effective!
- MapReduce works by breaking processing into the following 2 phases:
- Map (inherently parallel – each list el. processed ind.)
- Reduce (inherently sequential)
Map Function
- Applies to a list
- map(function, list) calls function(item) for each of the list’s items and returns a list of the return values. For example, to compute some cubes:
>>> def cube(x): return x*x*x
…
>>> map(cube, range(1, 11))
[1, 8, 27, 64, 125, 216, 343, 512, 729, 1000, 1331]
Reduce Function
- Applies to a list
- reduce(function, list) returns a single value constructed by calling the binary function on the first two items of the list, then on the result and the next item, and so on…
- For example, to compute the sum of the numbers 1 through 11:
- >>> def add(x,y): return x+y
…
- >>> reduce(add, range(1, 11))
66
My view of MapReduce
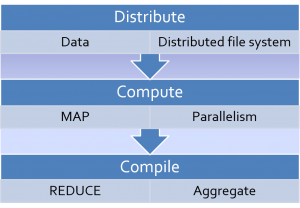
MapReduce
- A programming model & its associated implementation
- MapReduce is a patented software framework introduced by Google to support distributed computing on large data sets on clusters of computers (wiki defn.)
- Inspired by the map & reduce functions of functional programming (in a tweaked form)
- MapReduce is a framework for processing huge datasets on certain kinds of distributable problems using a large number of computers
- cluster (if all nodes use the same hardware) or as
- grid (if the nodes use different hardware)
- (wiki defn.)
- Computational processing can occur on data stored either in a filesystem (unstructured) or within a database (structured).
- Programmer need not worry about:
- Communication between nodes
- Division & scheduling of work
- Fault tolerance
- Monitoring & reporting
- Map Reduce handles and hides all these dirty details
- Provides a clean abstraction for programmer
Composable Systems
- Processing can be split into smaller computations and the partial results merged after some post-processing to give the final result
- MapReduce can be applied to this class of scientific applications that exhibit composable property.
- We only need to worry about mapping a particular algorithm to Map & Reduce
- If you can do that, with a little bit of high level programming, you are through!
- SPMD algorithms
- Data Parallel Problems
SPMD Algorithms
- It’s a technique to achieve parallelism.
- Tasks are split up and run on multiple processors simultaneously with different input data
- The robustness provided by MapReduce implementations is an important feature for selecting this technology for such SPMD algorithms
Hadoop
- MapReduce isn’t available outside Google!
- Hadoop/HDFS is an open source implementation of MapReduce/GFS
- Hadoop is a top-level Apache project being built and used by a global community of contributors, using Java
- Yahoo! has been the largest contributor to the project, and uses Hadoop extensively across its businesses
Hadoop & Facebook
- FB uses Hadoop to store copies of internal log and dimension data sources and use it as a source for reporting/analytics and machine learning.
- Currently FB has 2 major clusters:
- A 1100-machine cluster with 8800 cores and about 12 PB raw storage.
- A 300-machine cluster with 2400 cores and about 3 PB raw storage.
- Each (commodity) node has 8 cores and 12 TB of storage.
- FB has built a higher level data warehousing framework using these features called Hive
http://hadoop.apache.org/hive/
-
- Have also developed a FUSE implementation over hdfs.
- First company to abandon RDBMS and adopt Hadoop for implementation of a DW
A word about HIVE
- A data warehouse infrastructure built on top of Hadoop
- Enables easy data summarization, adhoc querying and analysis of large datasets data stored in Hadoop files.
- provides a mechanism to put structure on this data
- A simple query language called Hive QL (based on SQL) which enables users familiar with SQL to query this data.
- HIVE QL allows traditional map/reduce programmers to be able to plug in their custom mappers and reducers to do more sophisticated analysis which may not be supported by the built-in capabilities of the language.
Hadoop & Yahoo
YAHOO
- More than 100,000 CPUs in >36,000 computers running Hadoop
- Biggest cluster: 4000 nodes (2*4cpu boxes w 4*1TB disk & 16GB RAM)
- Used to support research for Ad Systems and Web Search
- Also used to do scaling tests to support development of Hadoop on larger clusters.
HDFS
- Data is organized into files & directories
- Files are divided into uniform sized blocks (64 MB default) & distributed across cluster nodes
- Blocks are replicated ( 3 default)to handle HW failure
- Replication for performance & fault tolerance
- Checksum for data corruption detection & recovery
Word Count using Map Reduce
- Mapper
- Input: <key: offset, value:line of a document>
- Output: for each word w in input line output<key: w, value:1>
Input: (The quick brown fox jumps over the lazy dog.)
Output: (the, 1) , (quick, 1), (brown, 1) … (fox,1), (the, 1)
- Reducer
- Input: <key: word, value: list<integer>>
- Output: sum all values from input for the given key input list of values and output <Key:word value:count>
Input: (the, [1, 1, 1, 1,1]), (fox, [1, 1, 1]) …
Output: (the, 5)
(fox, 3)
Map Reduce Architecture
- Map Phase
- Map tasks run in parallel – output intermediate key value pairs
- Shuffle and sort phase
- Map task output is partitioned by hashing the output key
- Number of partitions is equal to number of reducers
- Partitioning ensures all key/value pairs sharing same key belong to same partition
- The map output partition is sorted by key to group all values for the same key
- Reduce Phase
- Each partition is assigned to one reducer.
- Reducers also run in parallel.
- No two reducers process the same intermediate key
- Reducer gets all values for a given key at the same time
Strengths of MapReduce
- Provides highest level of abstraction (as on date)
- Learning curve – manageable
- Highly scalable
- Highly fault tolerant
- Economical


